An extremely abbreviated overview of Machine Learning through the lens of Portraiture. Thanks to Golan Levin for compiling many of these examples here.
As with ‘traditional’ generative art (e.g. Vera Molnár), artists using machine learning (ML) continue to develop programs that render an infinite variety of forms, and these forms are still characterized (or parameterized) by variables. What’s interesting about the use of ML in the arts, is that the values of these variables are no longer specified by the artist. Instead, the variables are now deduced indirectly from the training data that the artist provides. As Kyle McDonald has pointed out, machine learning is programming with examples, not instructions.
The use of ML typically means that the artists’ new variables control perceptually higher-order properties. (The parameter space, or number of possible variables, may also be significantly larger.) The artist’s job becomes one of selecting or creating training sets, and deftly controlling the values of the neural networks’ variables.
DeepDream (2015) is a computer vision program created by Google engineer Alexander Mordvintsev that uses a convolutional neural network to find and enhance patterns in images via algorithming a dream-like hallucinogenic appearance in the deliberately over-processed images


Deep Dream is computer program that locates and alters patterns that it identifies in digital pictures. Then it serves up those radically tweaked images for human eyes to see. The results veer from silly to artistic to nightmarish, depending on the input data and the specific parameters set by Google employees’ guidance.
One of the best ways to understand what Deep Dream is all about is to try it yourself. Google made its dreaming computers public to get a better understanding of how Deep Dream manages to classify and index certain types of pictures. You can upload any image you like to Google’s program, and seconds later you’ll see a fantastical rendering based on your photograph.
another explanation here
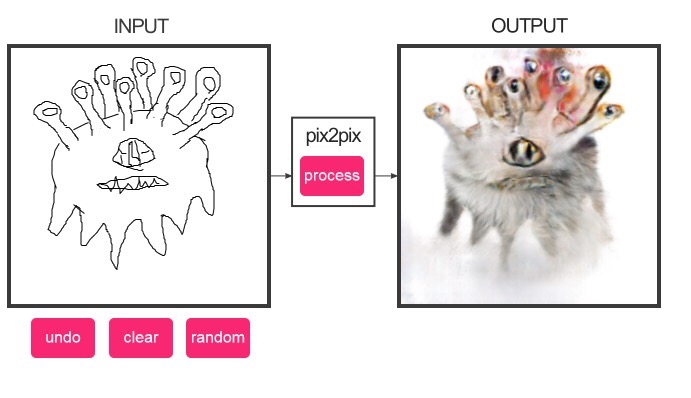
Edges2Cats

Trained on about 2k stock cat photos and edges automatically generated from those photos. Generates cat-colored objects, some with nightmare faces. The best one I’ve seen yet was a cat-beholder. TRY IT HERE
Janelle Shane, GANcats (2019)

It’s worth pointing out that when training sets are too small, the synthesized results can show biases that reveal the limits to the data on which it was trained. For example, above are results from a network, trained by artist-researcher Janelle Shane, that synthesizes ‘realistic’ cats. But many of the cat images in the training dataset were from memes. And some cat images contain people… but not enough examples from which to realistically synthesize one. Janelle Shane points out that cats, in particular, are also highly variable. When the training sets can’t capture that variability, other misinterpretations show up as well.
Janelle Shane is particularly well-known for her humorous 2017 project in which she trained a neural network to generate the names and colors of new paints:

Machine Learning in the Wild
Google Arts & Culture App
Image Synthesis from Yahoo’s open_nsfw (2016)
Yahoo’s open sourced neural network, open_nsfw, is a fine tuned Residual Network which scores images on a scale of to on its suitability for use in the workplace. In the documentation, Yahoo notes
“Defining NSFW material is subjective and the task of identifying these images is non-trivial. Moreover, what may be objectionable in one context can be suitable in another.”
https://www.gwern.net/docs/ai/2016-goh-opennsfw.html


THIS PERSON DOES NOT EXIST
Thispersondoesnotexist is one of several websites that have popped up in recent weeks using StyleGAN to churn out images of people, cats, anime characters and vacation homes

This Foot Does Not Exist by MSCHIF
https://thisfootdoesnotexist.com/
by MSCHF, a Brooklyn-based creative collective that spews out a constant stream of new, interesting digital/real-world projects. They’re latest creation is This Foot Does Not Exist (TFDNE), a bot that you text to receive GAN (Generative Adversarial Network) generated foot photos.

text 405-266-1401 and ask for feet pix

Mario Klingemann, Face Feedback III

Klingemann puts a generative adversarial network into feedback with itself.
Image Synthesis from Yahoo’s open_nsfw
Memo Akten, Learning to See (2017) • (video)

Akten uses input from a webcam to interactively shape the response from a GAN, as it tries its hardest to replicate the camera view given what it has learned about images.
A related project is Mario Klingemann’s interactive Fingerplay (2018):

White Collar Crime Risk Zones, Sam Lavigne et al.

White Collar Crime Risk Zones uses machine learning to predict where financial crimes are mostly likely to occur across the US. The project is realized as a website, smartphone app and gallery installation.
Pareidolia, Erwin Driessens & Maria Verstappen, 2019.
In the artwork Pareidolia* facial detection is applied to grains of sand. A fully automated robot search engine examines the grains of sand in situ. When the machine finds a face in one of the grains, the portrait is photographed and displayed on a large screen.

Stephanie Dinkins, Conversations with Bina48

Artist Stephanie Dinkins and Bina48, one of the worlds most advanced social robots, test this question through a series of ongoing videotaped conversations. This art project explores the possibility of a longterm relationship between a person and an autonomous robot that is based on emotional interaction and potentially reveals important aspects of human-robot interaction and the human condition.
Mitra Azar, DoppelGANger 2019
Mitra Azar’s project DoppelGANger consists of a series of interventions in which he disseminates posters of missing persons on the streets of Cuba, Paris, Milan and other cities in the world. The images and texts on these posters are the results of algorithms based on generative adversarial networks (or GAN) – machine learning sytems based on neural networks. After being trained on large datasets of photographs and written data respectively, these algorithms are able to generate photorealistic yet completely fictional portraits and coherent paragraphs from scratch… Are these images of missing people waiting for their real counterparts to be ‘found’ in the streets or yet to be born? Are they computational ghosts of machine produced-visions of how humankind should look like or are they digital doppelgangers, proxies of real humans?


DeepTomCruise
Body, Movement, Language: AI Sketches With Bill T. Jones, Bill T. Jones & Google Creative Lab, 2019
Explore the intersections of art, technology, identity and the body with this suite of PoseNet and voice experiments developed by Google Creative Lab and pioneering choreographer, Tony Award winner and MacArthur Fellow, Bill T. Jones.
All four experiments in the collection were built using the PoseNet machine learning model running on Tensorflow.js. Bill and the team took full advantage of the creative possibilities of pose estimation technology in designing unique interactions based on voice and movement. Since PoseNet can be accessed by anyone using a web-browser and a simple camera, the experiments invite users everywhere to explore the creative possibilities of their own bodies and make new connections with Bill’s iconic solo, 21.



Teachable Machine
“Teachable Machine is a web-based tool that makes creating machine learning models fast, easy, and accessible to everyone.”
click this link—> https://teachablemachine.withgoogle.com/train and build an image or pose project.
Intro to teachable machines here with ~Dan Schiffman~
People’s Guide to AI by MIMI ONUOHA and MOTHER CYBORG (ALSO KNOWN AS DIANA NUCERA)
The People’s Guide to Artificial Intelligence is an educational and speculative approach to understanding artificial intelligence (AI) and its growing impact on society. The 78-page booklet explores the forms AI takes today and the role AI-based technologies can play in fostering equitable futures. The project resists narratives of dystopian futures by using popular education, design, and storytelling to lay the groundwork for creative imaginings.Written by Mimi Onuoha and Diana Nucera a.k.a. Mother Cyborg, with design and illustration by And Also Too.


Robbie Barrat, Neural Network Balenciaga (2018)

Barrat uses a corpus of images from Balenciaga runway shows and catalogues, to generate outfits which are novel but at the same time heavily inspired by Balenciaga’s recent fashion lines. Barrat points out that his network lacks any contextual awareness of the non-visual functions of clothing (e.g. why people carry bags, why people prefer symmetrical outfits) – and thus produces strange outfits that completely disregard these functions — such as a pair of pants with a wrap-around bag attached to the shin, and a multi-component asymmetrical coat including an enormous blue sleeve.
BY DANIEL SANNWALD X BEAUTY_GAN for Kylie Cosmetics

Two design studios – Selam X in Berlin and ART404 in New York – have teamed up to initiate a different application of AI in the realm of beauty. Comprised of computer scientists, art directors, coders and designers, the group is a global constellation of engineers and creatives who have created Beauty_GAN, a type of artificial intelligence algorithm that uses machine learning to produce imagery. In this case, beauty imagery, and specifically, the images of Kylie Jenner’s face in this publication. But two design studios – Selam X in Berlin and ART404 in New York – have teamed up to initiate a different application of AI in the realm of beauty. Comprised of computer scientists, art directors, coders and designers, the group is a global constellation of engineers and creatives who have created Beauty_GAN, a type of artificial intelligence algorithm that uses machine learning to produce imagery. In this case, beauty imagery, and specifically, the images of Kylie Jenner’s face in this publication. More here
Animate Sketches
https://sketch.metademolab.com/canvas
ANIMATED DRAWINGS
PRESENTED BY META AI RESEARCH

EXIT TICKET / PARTICIPATION DELIVERABLE: Please choose a link from the list below and tells us (in a sentence or two) what the tool does in the class chat on discord!
ML Creative Tools:
https://narrative-device.herokuapp.com/createstory
https://storage.googleapis.com/chimera-painter/index.html
https://www.myheritage.com/deep-nostalgia
https://artsexperiments.withgoogle.com/xdegrees/8gHu5Z5RF4BsNg/BgHD_Fxb-V_K3A/
https://artsandculture.google.com/experiment/blob-opera/AAHWrq360NcGbw?hl=en
https://www.clevelandart.org/art/collection/share-your-view
https://thispersondoesnotexist.com/
https://distill.pub/2019/activation-atlas/

{kind=link}
Leave a comment